Quick Start
This tutorial is intended to provide a quick introduction to SoupJS. In it, we’ll be creating a web scraper that can scrape Indeed, a website that contains job postings. By the end of this tutorial, you’ll understand how to use SoupJS for your own projects.
Getting Started
To get started, you should have Node installed. Once you have Node installed, create a folder named /indeed-scraper and head over it. Once you’re there, you can install the library in the command line, using NPM, a package manager for Node:
npm i soupjs-lib
Goals
We should also talk about what we want to accomplish with our program. As mentioned before, Indeed provides job postings. Our goal is to be able to search for jobs of a certain type in a specific area. For the sake of this article, let’s say we’re searching for jobs involving programming in the zip code 01020. For each job posting, we want to see the following information:
- job title - for example, “Senior software developer”
- company - for example, “Acne, Inc.”
- location - for example, “New York City, New York”
- salary - for example, “$50,000 - $100,000 per year”
- job link - for example, “https://www.indeed.com/company/aDept-Consultants/jobs/Java-Developer-bf65dec587f42d47?fccid=5c4609aeec2de08a&vjs=3”
Now that we’ve got our goals nailed down, let’s start writing the program!
Writing the Program
Now we can write the program. Create a new file in /indeed-scraper and name it index.js. Let’s start by requiring SoupJS:
const soupjs = require("soupjs-lib");
Before we go any further, let’s actually look at Indeed’s website and determine what we’re working with here. Head over to indeed.com, and you’ll be presented with a form asking you for a job and location. Fill it out, and you’ll be redirected to a URL that looks something like:
https://www.indeed.com/jobs?q=programmer&l=01020
You’ll notice that the URL contains the name of the job we’re searching for and the location. According to our goals, we want to be to search for jobs in a specific area. Therefore, we can substitute “programmer” and “01020” in the link above to get that result! Here’s the code for that:
const JOB_TITLE = "programmer";
const LOCATION = "01020";
soupjs.scrape(`https://www.indeed.com/jobs?q=${JOB_TITLE}&l=${LOCATION}`).then(res => {
// Code here
}).catch(err => console.log(err));
This is the first time we’re seeing SoupJS. In this case, we’re using SoupJS’s scrape() function. This takes in a URL(although it can also take in a local file, per the Docs), and returns a object, whose class is Soup, that we can use to search the content at the URL.
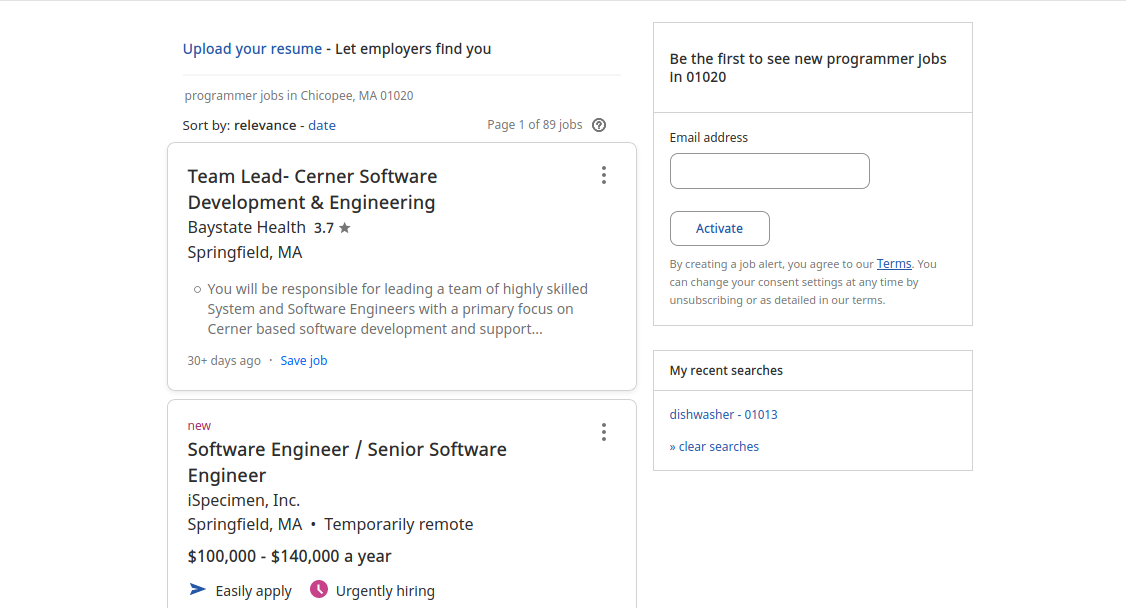
Now we can take a look at the content of the website. It should look something like the above. The information we need for each job posting is located in each of the cards shown. If you inspect(right-click on one of the cards, and press “Inspect”) the source of the page, you’ll notice that each of the cards use a class called “.jobsearch-SerpJobCard”. The object scrape() returns can be used to find all of the elements with this class.
soupjs.scrape(`https://www.indeed.com/jobs?q=${JOB_TITLE}&l=${LOCATION}`).then(res => {
// Get job postings
let jobPostings = res.findAll(".jobsearch-SerpJobCard");
console.log(jobPostings);
}).catch(err => console.log(err));
In the code above, we just used findAll(), a method Soup provides to find all elements on a page belonging to a CSS selector. This effectively allows us to find all the job postings on the current page, which gets returned to us in the form of a array. If you look at the output in the console, you’ll see that each item in the array is a Tag object.
Now let’s loop through each of the job postings:
soupjs.scrape(`https://www.indeed.com/jobs?q=${JOB_TITLE}&l=${LOCATION}`).then(res => {
// Get job postings
let jobPostings = res.findAll(".jobsearch-SerpJobCard");
for (let posting of jobPostings) {
// Loop through job postings and get: job title, company, location, salary, and job link
}
}).catch(err => console.log(err));
As mentioned before, each item in jobPostings is a Tag object. Tag is similar to Soup in that it provides a method called findAll(). Like the Soup class, it also provides a method called find(), which finds the first element matching a CSS selector. These are covered in more detail in the Docs.
However, when we use find() or findAll() inside a Tag object, we’re searching within the scope of a element, rather than the entire source code of a web page. We’re going to use find() right now to search for the necessary information we need:
soupjs.scrape(`https://www.indeed.com/jobs?q=${JOB_TITLE}&l=${LOCATION}`).then(res => {
// Get job postings
let jobPostings = res.findAll(".jobsearch-SerpJobCard");
for (let posting of jobPostings) {
// Loop through job postings and get: job title, company, location, salary, and job link
let values = {
"Job title": posting.find(".jobtitle"),
"Company": posting.find(".company"),
"Location": posting.find(".location"),
"Salary": posting.find(".salaryText")
};
for (let [key, value] of Object.entries(values)) {
// Log values
if (value == null) {
// Value not provided
console.log(`${key}: Not provided`);
continue;
}
console.log(`${key}: ${value.text}`);
}
}
}).catch(err => console.log(err));
As you can see, we’re using find() to find the job title, company, location, and salary of each job posting. All of this information is stored inside a dictionary/object, which we can loop through and log to the console. If a value isn’t provided(such as salary, which often depends on experience), we simply log “Not provided”. Easy!
Looking through the current code and the source code of the job postings, we can see that:
- job title is marked by a class known as “.jobtitle”
- company is marked by a class known as “.company”
- location is marked by a class known as “.location”
- salary is marked by a class known as “.salaryText”
The last thing we need to do is log the job link, which provides more information about the job. If you thoroughly inspect one of the cards, you’ll notice that the job title is actually a link, which leads to a page with in-depth information about the job. You can confirm this by doing something like this:
console.log(values["Job title"].tagName);
// => a
The Tag class is what is providing such functionality. Besides accessing the tag name of an element, you can also access the text and attributes of the element, which are described in more detail in the Docs.
This means we can simply get the href attribute of the link, and log that to the console. To do so, we can use a method Tag provides that Soup doesn’t: getAttr(). This returns the value of a given attribute.
soupjs.scrape(`https://www.indeed.com/jobs?q=${JOB_TITLE}&l=${LOCATION}`).then(res => {
// Get job postings
let jobPostings = res.findAll(".jobsearch-SerpJobCard");
for (let posting of jobPostings) {
// Loop through job postings and get: job title, company, location, salary, and job link
let values = {
"Job title": posting.find(".jobtitle"),
"Company": posting.find(".company"),
"Location": posting.find(".location"),
"Salary": posting.find(".salaryText")
};
for (let [key, value] of Object.entries(values)) {
// Log values
if (value == null) {
// Value not provided
console.log(`${key}: Not provided`);
continue;
}
console.log(`${key}: ${value.text}`);
}
if (values["Job title"] != null) {
// Get link to job posting
let baseURL = values["Job title"].getAttr("href").slice(1);
console.log(`Link posting: https://www.indeed.com/${baseURL}`);
} else {
console.log("Link posting: Not provided");
}
console.log("\n");
}
}).catch(err => console.log(err));
Notice that we use getAttr("href") to get the value of the link. We then use slice(1) to remove the “/” found at the beginning of the link.
Congratulations, you just wrote a simple web scraper in SoupJS!
Code not logging anything to the console? Try running the program multiple times. Indeed’s page is dynamically loaded, so information might not always be returned.
Conclusion/Next Steps
Now that you’re done with this tutorial, you have a basic understanding of SoupJS! The next step would be to take a look at the Docs, which is actually a shorter read than this page.